


TCP #47: Zero-ETL Architectures with Amazon MSK
Building the Data Backbone of Modern Applications

You can also read my newsletters from the Substack mobile app and be notified when a new issue is available.

The Cloud Playbook is now offering sponsorship slots in each issue. If you want to feature your product or service in my newsletter, explore my sponsor page
In today's digital economy, data doesn't just grow; it flows.
Organizations increasingly need to process and analyze information as it's created, not hours or days later. This shift from batch to real-time processing has made Apache Kafka a cornerstone technology in modern data architectures.
Amazon Managed Streaming for Kafka (MSK) brings Kafka's power to AWS as a fully managed service, eliminating much of the operational overhead while maintaining compatibility with the Kafka ecosystem.
When appropriately designed, MSK can be the foundation for truly Zero-ETL architectures, where data flows seamlessly from producers to consumers without traditional extract, transform, and load processes.
In this post, I'll explore leveraging Amazon MSK to build resilient, scalable Zero-ETL pipelines that can transform your organization's data management.
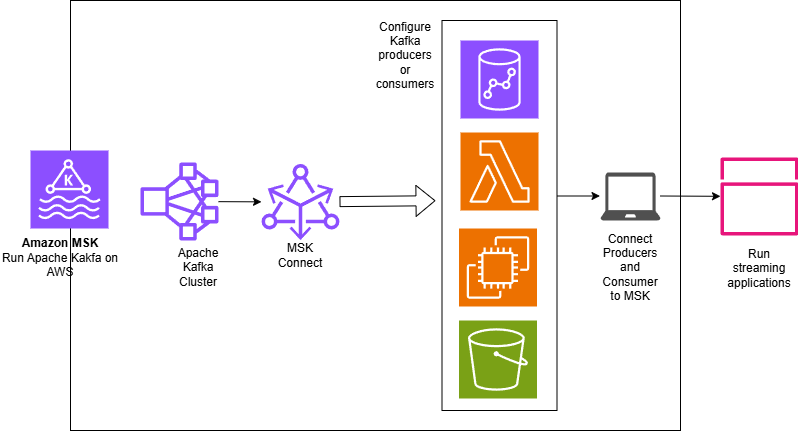
The Promise of MSK in Zero-ETL Architectures
Traditional ETL processes often introduce delays, require significant engineering resources, and create brittle dependencies.
With Amazon MSK at the center of your data architecture, you can:
Process data in real-time as events occur
Decouple producers and consumers for greater flexibility
Scale horizontally to handle growing data volumes
Preserve the complete data history for reprocessing when needed
Integrate natively with numerous AWS services
Perhaps most importantly, MSK enables a publish-subscribe model where producers don't need to know who will consume their data. This fundamental shift eliminates the need to build and maintain point-to-point integrations between systems.
Building Blocks of an MSK-Based Zero-ETL Architecture
Let's explore the key components that make up a comprehensive Zero-ETL solution using Amazon MSK:
1. Amazon MSK Cluster
The central nervous system of your architecture, an MSK cluster:
Provides durable storage for event streams
Handles partitioning for parallel processing
Manages replication for high-availability
Scales to accommodate growing workloads
When creating your MSK cluster, consider these key configurations:
Broker size and count based on throughput needs
Availability zones for resilience (minimum of two recommended)
Storage throughput mode (provisioned vs. throughput-optimized)
Encryption settings for data in transit and at rest
2. MSK Connect for Seamless Integration
One of the most powerful features for Zero-ETL workflows is MSK Connect, which provides managed Kafka Connect workers that can move data between Kafka and other systems without custom code.
MSK Connect S3 Sink Connector Configuration
{
"connector.class": "io.confluent.connect.s3.S3SinkConnector",
"tasks.max": "4",
"topics": "web-events,app-events,system-metrics",
"s3.region": "us-east-1",
"s3.bucket.name": "my-analytics-data-lake",
"topics.dir": "raw-events",
"flush.size": "10000",
"rotate.schedule.interval.ms": "300000",
"storage.class": "io.confluent.connect.s3.storage.S3Storage",
"format.class": "io.confluent.connect.s3.format.parquet.ParquetFormat",
"parquet.codec": "snappy",
"partitioner.class": "io.confluent.connect.storage.partitioner.TimeBasedPartitioner",
"path.format": "'year'=YYYY/'month'=MM/'day'=dd/'hour'=HH",
"locale": "en-US",
"timezone": "UTC",
"schema.compatibility": "FULL",
"transforms": "addMetadata",
"transforms.addMetadata.type": "org.apache.kafka.connect.transforms.InsertField$Value",
"transforms.addMetadata.timestamp.field": "s3_ingestion_time"
}
With pre-built connectors for popular systems, you can easily:
Stream data to S3 for your data lake
Feed OpenSearch for real-time search and analytics
Update DynamoDB tables as events occur
Sync with RDS databases for operational workloads
Send data to Redshift for analytical queries
The beauty of MSK Connect is that once configured, these data flows run continuously and automatically, embodying the Zero-ETL principle.
3. Lambda for Custom Processing
While MSK Connect handles many common scenarios, AWS Lambda provides flexibility for custom transformations and routing:
import json
import base64
import boto3
from datetime import datetime
# Initialize DynamoDB client
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('customer-profile-updates')
def lambda_handler(event, context):
processed_records = 0
for record in event['records']:
# Decode the base64-encoded Kafka message
payload = base64.b64decode(record['value']).decode('utf-8')
message = json.loads(payload)
# Extract customer ID and enrich the record
customer_id = message.get('customerId')
if not customer_id:
print(f"Warning: Record missing customerId: {message}")
continue
# Add processing timestamp
message['processedAt'] = datetime.utcnow().isoformat()
# Write to DynamoDB
try:
table.put_item(Item={
'customerId': customer_id,
'timestamp': message.get('eventTime', datetime.utcnow().isoformat()),
'profileData': message
})
processed_records += 1
except Exception as e:
print(f"Error writing to DynamoDB: {str(e)}")
print(f"Successfully processed {processed_records} records")
return {
'statusCode': 200,
'body': json.dumps(f'Processed {processed_records} records')
}
Lambda functions can be triggered by new messages in your MSK topics to:
Transform data formats (e.g., XML to JSON)
Enrich events with additional context
Filter out unwanted records
Route data based on content
Aggregate events for efficiency
For optimal performance, consider configuring your Lambda consumer group to process multiple partitions in parallel while maintaining exactly-once semantics.
4. Kafka Streams and KSQL for Stream Processing
For more complex stream processing, you can use:
Kafka Streams API for building Java applications that transform, aggregate, or join streams
KSQL for SQL-like stream processing without writing code
These technologies let you implement sophisticated processing logic while maintaining the Zero-ETL principle, as all processing happens within the Kafka ecosystem.
Real-World Zero-ETL Patterns with MSK
Let's explore some common patterns that exemplify Zero-ETL with MSK:
Pattern 1: Real-Time Data Lake Ingestion
Organizations must populate their data lakes with fresh data while preserving the original events for compliance and reprocessing.
Solution:
Configure MSK Connect with the S3 Sink Connector
Set up partitioning by date/time for optimal query performance
Choose Parquet or Avro format for storage efficiency
Implement schema registry for evolution
Benefits:
Data lands in S3 within seconds of being produced
The original event structure is preserved
No custom code required
Scales automatically with volume increases
Pattern 2: Multi-Environment Replication
Enterprises must share data across development, testing, and production environments while maintaining isolation.
Solution:
Set up MSK Replication to copy topics between clusters
Configure topic-level filtering for security
Implement cross-region replication for disaster recovery
Use MirrorMaker 2.0 for advanced replication needs
Benefits:
Environments remain isolated but share necessary data
No custom ETL code to maintain
Changes propagate automatically
Supports global distribution of data
Pattern 3: Event-Driven Microservices
Building responsive microservices that react to changes across the organization.
Solution:
Each service publishes domain events to MSK
Services subscribe only to relevant topics
Use consumer groups for load balancing
Implement dead-letter queues for error handling
Benefits:
Services are loosely coupled
New consumers can access historical data
The system handles backpressure gracefully
Scales horizontally as needs grow
Best Practices for MSK-Based Zero-ETL
To ensure your MSK-based Zero-ETL architecture succeeds:
1. Schema Management
Implement a schema registry to:
Enforce compatibility as schemas evolve
Document the structure of your events
Enable consumers to interpret data correctly
Support multiple serialization formats
2. Monitoring and Alerting
Set up comprehensive monitoring:
Track broker health and performance
Monitor consumer lag to identify processing delays
Alert on connectivity issues or throughput drops
Create dashboards for visibility across teams
3. Security and Compliance
Implement proper security controls:
Use IAM for authentication and authorization
Encrypt data in transit and at rest
Implement network isolation with private VPC
Audit access and changes to configuration
4. Cost Optimization
Control costs while maintaining performance:
Right-size your brokers based on actual usage
Implement topic compaction where appropriate
Use tiered storage for historical data
Monitor and adjust as workloads change
Challenges and Solutions in MSK Zero-ETL Architectures
While powerful, MSK-based Zero-ETL is not without challenges:
1. Schema Evolution
As your systems evolve, so must your data structures.
Solution: Implement a schema registry with compatibility checks and use formats like Avro or Protobuf that support evolution. Plan for backward compatibility in your data models.
2. Exactly-Once Semantics
Some use cases require guarantees that events are processed exactly once.
Solution: Use Kafka's transactional API, idempotent producers, and consumer offsets to achieve exactly-once semantics. Design consumers to handle potential duplicates gracefully.
3. Reprocessing Historical Data
Sometimes, you need to reprocess data with new logic.
Solution: Configure adequate retention periods for your topics, implement consumer groups with explicit offset management, and design your processing to be idempotent.
Getting Started with MSK Zero-ETL
Ready to implement your own MSK-based Zero-ETL architecture?
Here's a roadmap:
Start small: Identify a specific use case with a clear value
Plan your topics: Design a thoughtful topic structure with partitioning in mind
Set up infrastructure: Deploy your MSK cluster with appropriate sizing
Implement producers: Begin sending data to your topics
Add consumers: Start with simple consumers and add complexity gradually
Monitor and optimize: Watch for bottlenecks and adjust as needed
Final Thoughts
As organizations generate more data faster, traditional ETL approaches become increasingly untenable.
Amazon MSK offers a path to true Zero-ETL architectures where data flows continuously and seamlessly between systems.
By embracing event streaming as a core architectural principle and leveraging MSK's managed capabilities, you can build data pipelines that are:
More responsive to business needs
More resilient to failures
More adaptable to changing requirements
More scalable as volumes grow
Next Steps and Resources
To dive deeper into MSK-based Zero-ETL:
Explore the AWS documentation: Amazon MSK Developer Guide
Try MSK Connect: Getting Started with MSK Connect
Learn Kafka fundamentals: Apache Kafka Documentation
That’s it for today!
Did you enjoy this newsletter issue?
Share with your friends, colleagues, and your favorite social media platform.
Until next week — Amrut
Whenever you’re ready, there are 4 ways I can help you:
NEW! Get certified as an AWS AI Practitioner in 2025. Sign up today to elevate your cloud skills. (link)
Are you thinking about getting certified as a Google Cloud Digital Leader?
Here’s a link to my Udemy course, which has helped 628+ students prepare and pass the exam. Currently, rated 4.37/5. (link)
Free guides and helpful resources: https://thecloudplaybook.gumroad.com/
Sponsor The Cloud Playbook Newsletter:
https://www.thecloudplaybook.com/p/sponsor-the-cloud-playbook-newsletter
Get in touch
You can find me on LinkedIn or X.
If you wish to request a topic you would like to read, you can contact me directly via LinkedIn or X.